pandas의 데이터프레임에서 특정 조건의 행열을 뽑아내는 함수는 loc와 iloc가 있습니다. loc가 칼럼명을 사용한 조건으로 탐색한다면, iloc는 index loc로 인덱스로 탐색합니다. 두 방식의 차이점에 대해 자세히 알아보겠습니다.
[ Contents ]
1. loc
df.loc[n:m, 'col1':'col2']
loc는 location의 준말로, 특정 위치에 있는 데이터를 찾아주는 함수입니다.
리스트 슬라이싱처럼 df.loc[n:m]은 n행부터 m행까지 추출해줍니다.
[Python] 리스트(List)란? 리스트 인덱싱(indexing)과 슬라이싱(slicing)
리스트 자료형에 대해 알아보고, 리스트 인덱싱과 슬라이싱을 예제와 함께 살펴보겠습니다. [ Contents ] 1. 리스트(List) 리스트(List): 여러 데이터들을 묶어서 목록화하는 자료형 데이터의 유형 상
star7sss.tistory.com
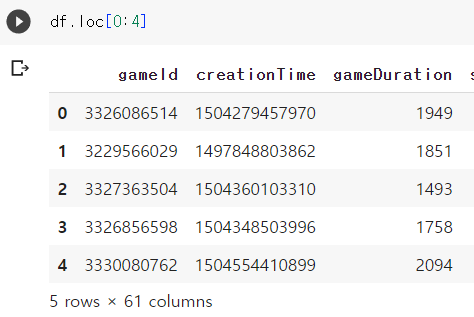
데이터프레임의 행 번호는 0부터 시작하며, n행부터 m행까지 보여줍니다. 주의할 점은 리스트 슬라이싱와 달리, m행도 포함됩니다. m-1까지가 아님을 유의해야 합니다.

그 외에는 리스트 슬라이싱과 마찬가지로 첫 행 혹은 마지막 행일 경우 인자를 생략할 수 있습니다.
df.loc[:4]는 df.loc[0:4]와 같고, 이는 0행부터 4행까지를 추출합니다.

loc[:]은 첫 행부터 마지막 행까지 전체를 추출하는 거겠죠? 물론 굳이 전체를 추출하는 데에 loc를 쓸 필요는 없겠지만요.

추가로 열의 범위도 지정할 수 있습니다.
열은 숫자가 아니라, '열 이름'으로 지칭해야 합니다.
2. iloc
df.iloc[n:m, i:j]
loc앞에 i(index)가 덧붙은 함수입니다. iloc는 인덱스 범위를 인자로 가지며, 리스트와 동일한 슬라이싱을 지원합니다.

앞서 loc의 [:4]는 0행부터 4행까지 총 5rows를 출력했지만, iloc는 0행부터 3행까지만 출력합니다. 즉, n부터 m-1행까지 출력합니다. (리스트 슬라이싱과 동일)

행의 경우 인덱스와 행 이름이 동일하기 때문에 상관이 없지만, 열은 이름이 별개로 있죠. loc는 이름(값)을 참조하지만, iloc는 인덱스를 참조하므로 열 번호를 사용해야 합니다.
3. 조건식을 이용한 loc와 iloc

loc와 iloc는 사실 조건식과 더불어서 많이 사용합니다. 해당 조건을 만족하는 데이터를 찾을 때 유용합니다.
df['gameDuration'] > 2000 을 만족하는 행만 찾아서 추출하며, 찾아보고 싶은 열도 지정할 수 있습니다.

물론 iloc도 조건식을 사용할 수는 있지만, 잘 사용하지는 않습니다. 왜냐하면 행/열 범위를 정해주기 어렵기 때문입니다.
우선 행 범위부터 df[].values를 통해 array로 바꿔줘야 하며, 열 범위 역시 인덱스로 지정하기가 상당히 까다롭습니다.
df.columns.get_loc('열 이름')으로 인덱스를 찾을 바에는 차라리 loc를 쓰는 게 낫죠. 그래서 조건식에는 주로 loc가 사용됩니다.

'Data Visualization > Python Lib' 카테고리의 다른 글
| [Pandas] 데이터셋의 결측치를 구하고 처리하는 방법 (isnull, dropna, fillna) (0) | 2023.06.16 |
|---|---|
| [Pandas] 데이터셋의 특정 타입 열만 조회하는 select_dtypes (0) | 2023.06.15 |
| [Pandas] 데이터셋의 행과 열의 개수 확인 shape (0) | 2023.06.12 |
| [Pandas] 엑셀파일 데이터셋으로 불러오기 (ft. 홈 디렉토리 확인) (0) | 2023.06.07 |
| [Numpy] 넘파이란? Numpy 설치방법과 주의할 점 (0) | 2022.04.08 |




댓글