혼동 행렬(Confusion Matrix)는 분류모델의 평가 지표로 많이 쓰이며, 그 지표에는 정확도, 정밀도, 재현율, 특이도, 조화평균이 있습니다. 아래에서는 각 평가지표를 구하는 방법과 쓰이는 예시를 살펴보겠습니다.
[ Contents ]
1. 혼동 행렬 (Confusion Matrix)

TP (True Positive): 실제도 양성이고, 예측도 양성 → 정답
TN (True Negative): 실제도 음성이고, 예측도 음성 → 정답
FP (False Positive): 실제는 음성인데, 예측은 양성 → 오답 (오탐지)
FN (False Negative): 실제는 양성인데, 예측은 음성 → 오답 (미탐지)
분류 모델에서 나올 수 있는 결과값을 행렬 형태로 정리한 걸 '혼동 행렬 (Confusion Matrix)'라고 합니다.
TP와 TN은 둘 다 같은 정답이지만, FP와 FN은 미묘한 차이가 있습니다. FP는 실제로는 아닌데 맞다고 오탐지한 경우이고, FN은 실제로 맞는데 아니라고 놓친 경우입니다.
분류 모델에 따라 오탐지에 리스크가 더 큰 경우가 있고, 미탐지에 리스크가 더 큰 경우가 있습니다. 이에 맞춰 평가 지표를 다르게 사용하며, 아래에서 더 자세히 살펴보겠습니다.
2. 평가 지표
1) 정확도 (Accuracy)

실제로 정확히 예측한 비율
분류 모델에서는 정확도가 제일 중요할 거 같지만, 의외로 데이터가 불균형한 경우에는 취약한 모습을 보입니다. 예를 들어 대한민국에서 한국인 판별 모델을 만든다면, 대부분 한국인일 확률이 높겠죠. 그러면 한국인이라고만 판별해도 80% 이상의 정확도를 갖게 됩니다.
이런 경우가 있기 때문에, 분류 모델에서는 단순 정확도 외에도 아래와 같은 평가지표도 고려하게 됩니다.
2) 정밀도 (Precision)

예측이 양성일 때, 실제로 맞춘 비율
양성으로 예측한 것 중에서 실제로 양성인 비율을 '정밀도'라고 합니다.
오탐지가 되면 안 되는 모델에서 중요하게 여기는 평가지표로, 예시로는 '스팸메일 탐지 모델'이 있습니다. 정상 메일이 스팸 메일로 분류되어 차단되면 안 되기에, 정밀도가 중요한 모델이라고 볼 수 있습니다. 그래서 오히려 스팸메일을 분류하지 못하는 경우가 더 많으며, 우리가 일상에서 스팸 메일을 보게 되는 이유이기도 합니다.
3) 재현율/민감도 (Recall/Sensitivity)

실제 양성 중에서 맞춘 비율
실제 양성 중에서 예측이 맞은 비율을 '재현율'이라고 합니다.
실제 양성을 놓치지 않고 꼼꼼이 찾아야 하는 경우에 해당 평가지표를 씁니다. 예를 들어 코로나 진단 시, 일반인에게 오진을 하는 것보다는 코로나 환자를 빠트리지 않고 진단하는 게 중요합니다. 그래서 코로나에 감염되지 않은 경우에도 검진 키트를 쓰면 간혹 코로나로 검진되는 경우가 꽤 있죠.
4) F1 Score(조화 평균)

정밀도와 재현율이 둘 다 중요할 때 사용하는 평가 지표
조화 평균은 수학에서 산술 평균의 역수로, 평균적인 변화율을 구할 때 주로 사용합니다. F1 Score은 0과 1 사이의 값을 가지며, 정밀도와 재현율이 모두 좋아야 1에 가깝게 나옵니다.
보통 정밀도와 재현율은 서로 반비례하는 관계를 가지는데, F1 Score는 둘 다 좋아야 하는 평가지표이므로 균형잡힌 성능 평가를 위해 사용합니다.
5) 특이도 (Specificity)
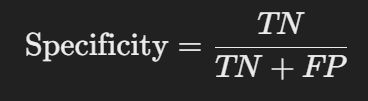
실제 음성 중에서 맞춘 비율
재현율(Recall)이 '실제 양성 중에서 맞춘 비율'이라면, 특이도(Specificity)는 '실제 음성 중에서 맞춘 비율'입니다. 양성과 음성은 정하기 나름이므로, 둘은 비슷한 평가지표이긴 하지만 보통은 양성을 기준으로 하므로 재현율을 더 많이 씁니다.
이렇듯 분류 모델의 평가지표에는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), 조화 평균(F1 Score), 특이도(Specificity)가 있고, 분류 모델에 따라 중요한 평가지표를 골라서 쓰게 됩니다. 모든 평가지표를 다 맞출 필요는 없으며, 용도에 따라 중요한 평가지표를 높여가는 방식으로 학습을 진행하시면 되겠습니다.

'AI (Artificial Intelligence) > DL (Deep Learning)' 카테고리의 다른 글
| [AI/DL] 부스팅(Boosting) 앙상블 기법의 개념과 절차, 특징 알아보기 (0) | 2025.04.04 |
|---|---|
| [AI/DL] 배깅(Bagging) 앙상블 기법의 개념 및 절차, 특징 알아보기 (0) | 2025.04.04 |
| [AI/DL] 매개변수 최적화 기법 종류: 확률적 경사 하강법(SGD), 모멘텀, AdaGrad, Adam (0) | 2025.04.04 |
| [AI/DL] 활성화 함수의 개념과 종류 (시그모이드, ReLU, 계단, 부호, tanh 함수) (0) | 2025.03.31 |
| [AI/DL] 딥러닝(Deep Learning)이란? 뉴런과 신경망 (0) | 2022.04.09 |




댓글