매개변수 최적화 기법의 개념에 대해서 알아보고, 그 종류를 살펴봅니다. (확률적 경사 하강법(SGD), 모멘텀, Adam)
[ Contents ]
1. 매개변수 최적화 (Parameter Optimization)
딥러닝에서 모델의 성능을 높이기 위해 파라미터(가중치, 편향)를 조정하는 과정
딥러닝에서는 학습을 통해 각 뉴런의 가중치와 편향을 조정합니다. 대량의 데이터 학습은 '입력에 따라 올바른 출력값을 도출하기 위한 매개변수(가중치, 편향) 조정 과정'으로, 효율적인 학습을 위해서는 매개변수 최적화가 필요하죠.
아래에서는 이러한 매개변수 최적화 방법에 대해서 알아보겠습니다.
2. 매개변수 최적화 기법
1) 확률적 경사 하강법(Stochastic Gradient Descent, SGD)

무작위 샘플 또는 작은 배치의 손실 함수(Loss Function) 기울기에 따라 조금씩 아래로 내려가, 최종적으로는 손실 함수가 가장 작은 지점에 도달하도록 하는 알고리즘
경사하강법에서 '확률' 개념을 추가한 방식입니다. 경사하강법과 달리 작은 배치 학습을 여러 번 반복하므로 속도가 빠르고, 일반화 성능이 좋은 편이죠. 탐색 경로가 지그재그로 크게 변하며, 기울기가 줄어드는 최적점 근처에서 느리게 진행하는 특징이 있습니다.
하지만 경사하강법과 마찬가지로 지역 극소점(local optimum)에 갇혀 전역 극소점(global optimum)을 찾지 못하는 경우가 많은 편입니다.
2) 모멘텀(Momentum)
기울기 방향으로 힘을 받으면 물체가 가속되듯이, 이전 업데이트 방향에 따라 관성을 갖고 학습
확률적 경사 하강법에서 '속도'라는 개념을 추가한 방식입니다. 기울기가 줄어들더라도 이전 속도에 기반해서 빠르게 최적점에 수렴할 수 있습니다.
마치 공이 구르는 듯한 학습과정을 거치며, 관성이 작용하여 진동과 그 폭이 줄어드는 효과가 있습니다.
3) Adagrad
손실 함수의 기울기가 큰 첫 부분에서는 크게 학습하다가, 최적점에 가까워질수록 학습률을 줄여 조금씩 적게 학습하는 방식
학습을 진행하면서 학습률을 점차 줄여가는 기법으로, 처음에는 뛰엄뛰엄 넓게 학습하다가 차츰 학습률을 줄여가며 최적점에 도달하는 방식입니다.
마치 맨 처음에 공부할 때에는 전체 내용을 훑어보다가, 그 이후에는 중요 내용만 유심히 보는 것과 비슷하죠.
4) Adam
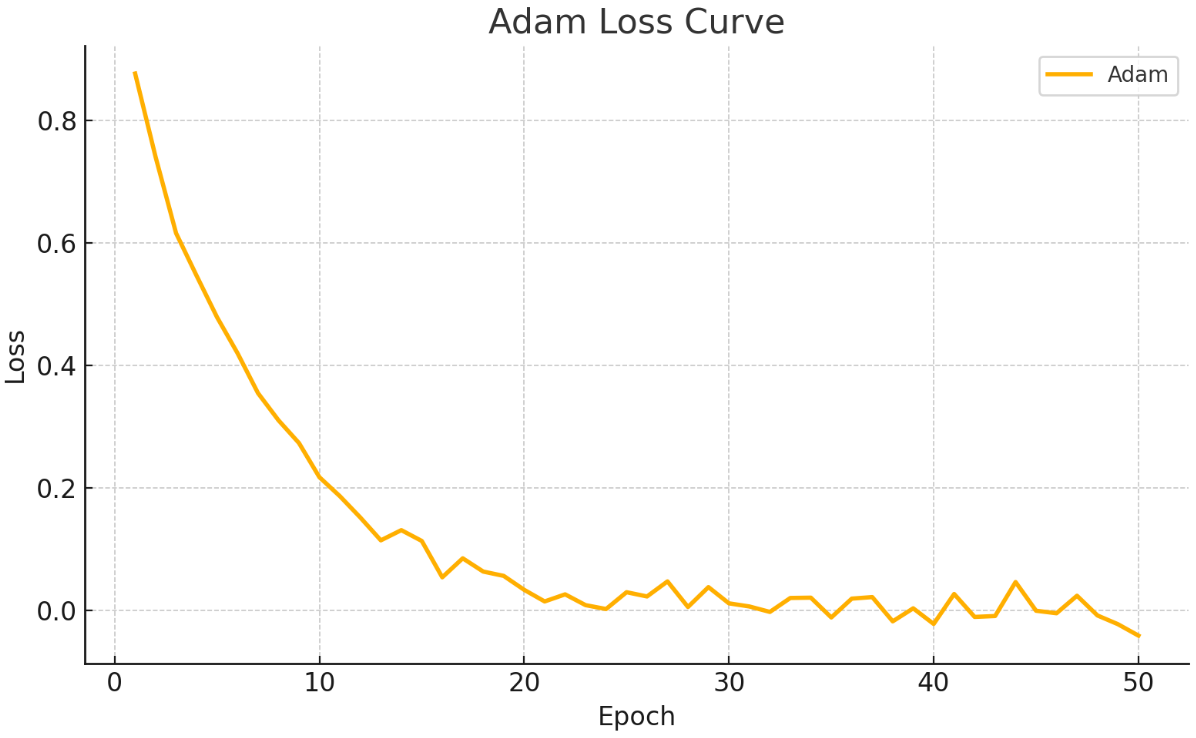
모멘텀 방식과 AdaGrad 방식의 장점을 합친 방식으로 이전 업데이트 방향에 따라 관성을 갖고 학습하되, 손실 함수의 기울기에 따라 학습률을 조정하는 방식
모멘텀 방식과 AdaGrad 방식의 장점을 합친 방식으로 두루 많이 사용됩니다. 마치 활성화 함수의 ReLU 같이 마땅히 쓸 게 없으면 보편적으로 사용하는 편입니다.
3. 매개변수 최적화 기법 비교
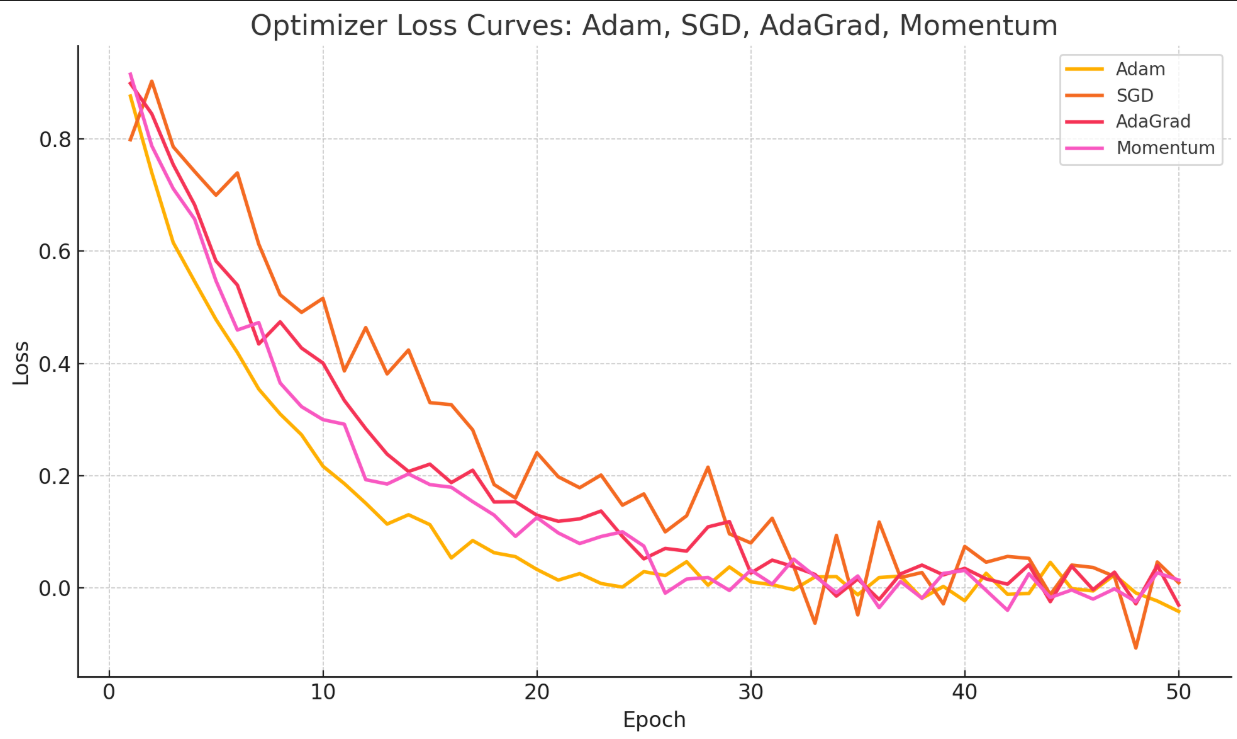
앞서 설명한 4가지 매개변수 최적화 기법의 성능을 비교한 그래프입니다.
4가지 기법 모두 최적점에 도달하지만, 안전성이나 손실함수 감소 속도에서 차이가 있습니다. Adam 기법이 비교적 안정적이고 손실함수 감소 속도도 빠른 편이죠.
물론 데이터 및 학습 모델에 따라 성능은 달라질 수 있으니, 이 점 고려해서 여러 가지 시험해보는 게 좋습니다.

'AI (Artificial Intelligence) > DL (Deep Learning)' 카테고리의 다른 글
| [AI/DL] 부스팅(Boosting) 앙상블 기법의 개념과 절차, 특징 알아보기 (0) | 2025.04.04 |
|---|---|
| [AI/DL] 배깅(Bagging) 앙상블 기법의 개념 및 절차, 특징 알아보기 (0) | 2025.04.04 |
| [AI/DL] 혼동 행렬 평가지표: 정확도, 정밀도, 재현율, 특이도, 조화 평균(F1 Score) (0) | 2025.04.03 |
| [AI/DL] 활성화 함수의 개념과 종류 (시그모이드, ReLU, 계단, 부호, tanh 함수) (0) | 2025.03.31 |
| [AI/DL] 딥러닝(Deep Learning)이란? 뉴런과 신경망 (0) | 2022.04.09 |




댓글