[ Project ]
1. 프로젝트 개요
- 분류: 데이터 분석
- 일시: 2021.10. ~ 2021.12.
- 스택: Pytorch, Python
- 주제: 리그 오브 레전드(LoL) 실시간 승률 예측
GitHub - jangThang/LoL_project: LoL_Realtime_Winrate_Predictor
LoL_Realtime_Winrate_Predictor. Contribute to jangThang/LoL_project development by creating an account on GitHub.
github.com
2. 프로젝트 소개

연간 이스포츠(E-sports)의 인기와 규모는 매년 커지고 있습니다. 코로나로 인해 언택트 시대가 도래하고 집에 있는 시간이 많아지면서 게임 및 이스포츠를 즐기고 관람하는 사람들이 크게 늘었습니다.

게임 전문 인터넷 방송인 트위치의 통계분석 사이트 트위치 트랙커에 따르면, 세계 트위치 시청자 수(하루 평균 기준)는 2015년 4월 50만 4090명에서, 2018년 4월 101만 1352명으로 3년 새 두 배 이상 증가했습니다.
직접 자신이 ‘하는’ 게임에서 ‘보는’ 게임으로 트렌드가 바뀌고 있으며, 이러한 현상은 코로나19로 외부활동이 제한되면서 더 가속화되고 있습니다.

이러한 사람들의 변화에 발맞춰, 2018년 아시안게임에서는 E-sports 종목을 시범적으로 운행했으며, 2022년 항저우 아시아게임에서 처음으로 E-sports를 정식종목으로 채택했습니다.

일반인들은 보기 어려운 E-sports
하지만, E-Sports는 게임 규칙이 단순하고 직관적이지 못합니다. 즉, 해당 게임을 플레이해본 경험이 없으면, 게임을 이해하기 어렵습니다. 반면 올림픽 종목 등 스포츠의 경우, 게임 규칙을 모르더라도 게임 스코어를 통해서 누가 유리한지 알 수 있으며, 게임 스코어를 얻거나 잃는 행위를 보고 쉽게 게임 규칙을 유추할 수 있습니다.
자신이 피겨스케이팅이나 핸드볼을 해본 적이 없어도, 쉽게 경기규칙을 이해하고 관람할 수 있는 기존 스포츠 경기와는 큰 차이가 있습니다.

1) 상대보다 많은 스코어를 얻기: 테니스, 양궁, 축구, 핸드볼, 태권도, 피겨스케이팅
2) 상대보다 빠르게, 높게 도달하기: 육상(달리기), 수영, 높이뛰기,
과거 크게 인기를 끌었던 스타크래프트 경기의 경우, 해당 게임을 아는 사람만 이해할 수 있고 게임을 모르는 사람은 그저 화려한 게임그래픽 영상에 불과했습니다. 올림픽 게임 종목의 경기 스코어처럼, 직관적인 수치지표가 필요하며 이는 ‘승률 예측’으로 대신할 수 있습니다.
선수가 어떤 플레이를 했을 때, 승률이 오른다면 해당 플레이는 Positive 하며 어떤 승리 목표를 가진 게임인지 대략 짐작할 수 있게 됩니다. 또한 선수들의 플레이 하나하나마다 역동적으로 변하는 예상 승률을 통해서 극적인 긴장감도 부여할 수 있습니다.
그래서 누가 유리한 건데?
경기 방송 중, 관중들의 실시간 채팅을 살펴보면 대부분 누가 유리한지, 지금 한 행동이 이득인지 손해인지에 대한 논의가 펼쳐집니다. 또한, 해당 게임을 하는 게이머나 해설자들도 승패에 어떤 영향을 미칠지 의견이 분분한 경우가 있습니다. 이럴 때에, 승률 예측기가 있다면 보다 정확한 지표를 제공할 수 있습니다.
게임 전략요소 분석
한편, 부가적으로 게이머들에게는 해당 게임의 승리 요소를 분석하여, 유용한 게임 전략을 수립하는 가이드라인을 제시할 수 있습니다. 게임 데이터들의 통계와 승률 분석기에서 중요하게 생각하는 feature를 확인해보면 유용한 승리 전략을 알아낼 수 있습니다.

여러 게임 중, 현재 전 세계적으로 인기 및 이스포츠 관람 수가 가장 많은 게임인 ‘League of Legend’(이하 LoL)를 분석하기로 했습니다. 2020년도 기준 LoL 월드 챔피언십(대회)의 최고 동시 시청자가 4595만 명에 달할 정도로 LoL은 큰 인기를 지닌 게임으로, 출시 이래로 국내 PC방 1등 게임을 지켜오고 있습니다.
대표 E-sports 게임인 LoL의 승률 예측기를 구현하고자 합니다.
● 프로젝트 배경
- '보는' 게임으로의 트랜드 전환과, 게임 영상 콘텐츠의 뚜렷한 성장세
- 아시안 게임, 올림픽 정식 종목으로 인정된 'E-Sports'
- 스포츠와 달리, 대중들이 쉽게 접할 수 없는 이스포츠의 특성
● 프로젝트 목표
- '실시간 승률'을 직관적인 수치지표를 제공함으로써, 대중들도 쉽게 이스포츠를 이해하고 즐김
- 데이터 정량분석을 통해 LoL 게임 도메인 이해
- RandomForest Classifier, Gradient Boosting Classifier, XGBoost, LightGBM으로 LoL 실시간 승률 예측
3. 기능 및 구성
1) LoL 데이터 정량분석
Riot Developer Portal
About the Riot Games API With this site we hope to provide the League of Legends developer community with access to game data in a secure and reliable way. This is just part of our ongoing effort to respond to players' and developers' requests for data and
developer.riotgames.com
LoL 데이터는 Riot API를 통해서 실시간으로 축적할 수 있습니다. 다만, 2분에 100개 정도만 데이터를 요청할 수 있는 제한이 있어서 시간이 다소 필요합니다.
또, API key 만료기간이 하루 정도이므로 갱신이 필요하고 예외 처리할 사항도 꽤 있었습니다.
Search | Kaggle
www.kaggle.com
데이터 수집이 여의치 않다면, 캐글에 있는 데이터셋을 이용하셔도 좋을 것 같습니다.

LoL 게임 데이터의 feature는 위와 같습니다. 승패에 영향을 줄 수 있는 항목들로, 각 feature의 관계와 승률에 미치는 영향성을 알아보기 위해 정량분석을 진행했습니다.

대부분의 게임은 4개 정도의 포탑을 부수고, 1용에서 끝이 납니다. 즉, 외곽 포탑이 깨지고 라인전이 끝나면 게임의 승패가 결정된다는 얘기입니다. '빨리빨리' 문화에 익숙한 한국 특성상, 넥서스가 파괴될 때까지 게임을 지속하기보다는 빠른 서렌으로 게임이 끝나는 경우가 많습니다.


반면, 억제기를 최대 10번까지 파괴한 초 장시간 경기도 있었습니다. 게임 내 억제기는 총 3개로, 파괴되면 5분 후에 재생성됩니다. 넥서스 주위의 억제기를 6번 이상 부셨다면, 매우 긴 시간 동안 게임을 진행한 것으로 예상할 수 있습니다.
해당 게임들은 평균게임보다 당연히 모든 지수가 높았고, 이런 수치들은 이례적인 경우이므로 제거했습니다.

승리팀과 패배팀의 수치를 비교 분석해보겠습니다. LoL은 상대 챔피언을 죽이는 서바이벌 게임이 아니라, 넥서스를 파괴하는 DOTA(AOS) 게임으로 당연히 승리팀의 타워 파괴 횟수가 압도적으로 많았습니다.
그 외의 수치도 승리팀이 패배팀보다 높았습니다.


그래프로 살펴보면 그 차이가 더 확연히 드러납니다. 그중 '타워'와 관련된 feature는 승리와 더 연관성이 높습니다.
처음으로 타워나 억제기를 부순 팀이 거의 승리했고, 타워 파괴 개수도 확연한 차이를 보였습니다.


Boxplot으로 살펴보면, 패배팀의 outlier가 돋보입니다. 전반적인 수치는 0에 가깝지만, 간혹 높은 경우가 있습니다. 이는 후반부까지 진행된 경기로 추측할 수 있고, 승리한 팀과 비슷하게 또는 약간 불리하게 게임을 진행하다 패배한 경우입니다. 이러한 경기들이 승률 예측하기 어려울 것으로 예상됩니다.

다음은 feature 간 상관관계 분석입니다. 강한 상관관계를 보이는 특성들을 살펴보면, 첫 에픽 몬스터/타워를 kill 한 팀이 이후에도 더 많이 kill 한다는 걸 쉽게 추측해볼 수 있습니다.
또한, 문지기 역할을 하는 tower를 부셔야만 안쪽에 있는 inhibitor를 파괴할 수 있으므로, 둘의 높은 상관관계도 쉽게 이해할 수 있습니다.

이는 앞서 본 상관관계표를 히트맵(hit map)으로 시각화한 자료입니다. 0.7 이상의 강한 상관관계를 갖는 feature들은 빨간색 네모로 표시해두었습니다. tower와 inhibitor, first와 kills의 높은 상관관계가 나타났으므로 후 feature engineering으로 feature 개수 [dimension]를 줄이는 것을 기대해볼 수 있습니다.
또한 LoL은 상대 기지의 타워와 넥서스를 부수는 공성게임 장르인 MOBA(AOS)이므로, Tower/Inhibitor 관련 feature들이 승리 요소와 높은 상관관계를 가지는 것도 쉽게 예상해볼 수 있습니다.
2) LoL 데이터 전처리

데이터셋은 총 17개의 columns과 217658개의 row로 이루어져 있습니다. win column을 보면 12개의 null이 있는 걸 확인할 수 있습니다. 비정상적으로 종료된 게임으로 예상되며 결측치를 제거합니다.
또, 정량분석에서 확인한 이상치(억제기를 6번 이상 파괴한 게임)도 제거합니다.

이후, 승리 여부나 first 특성과 같은 범주형 데이터를 Label Encoding 합니다. True/False, Male/Female과 같이 Binary feature는 하나의 값을 알면 다른 값을 알 수 있기 때문에, 굳이 One-Hot Encoding을 하지 않았습니다.
만약 범주가 3개 이상이라면, 인접 feature 간의 상관관계가 있다고 머신러닝이 오인하지 않도록 One-Hot Encoding을 해줘야 합니다.

수치형 데이터도 스케일링 해줍니다. StandardScaler는 각 특성의 평균을 0, 분산을 1로 변경하여 특성의 스케일을 맞춰줍니다. 즉 표준 정규분포 형태로 변환해줍니다. 반면, MinMaxScaler는 모든 특성이 0과 1 사이에 위치하도록 변경합니다.
두 스케일링 모두 이상치에 취약하므로, 이상치를 위와 같이 미리 제거해두어야 합니다. StandardScaler는 이상치가 있을 경우, 평균과 표준편차에 영향을 미쳐 균형 잡힌 척도를 보장할 수 없습니다. (변환된 데이터의 scatter가 매우 달라지게 됨) MinMaxScaler도 매우 작은 값이나 큰 값인 outlier에 매우 민감하며, 사전에 해당 이상치를 제거해줘야 합니다.
3) Random Forest Classifier

전처리된 데이터를 모델 학습에 사용합니다. 제일 먼저 Random Forest Classifier입니다. Random Forest는 bagging 또는 pasting 방식을 적용하는 결정 트리 앙상블 모델입니다.
위 랜덤포레스트 모델은 Bagging 방식을 사용했고, OOB로 평가했습니다. OOB는 out of bag로, 배깅에서 한 번도 샘플링되지 않는 데이터를 말합니다. Bagging Classifier는 기본값으로 중복을 허용하여 (bootstrap=True) 훈련 데이터셋의 크기만큼 샘플링합니다.
평균적으로 각 classifier에 63% 정도만 샘플링되며, 나머지 37% 정도는 훈련할 때 사용되지 않았으므로 해당 데이터는 validation 용도로 사용할 수 있습니다. (여사건의 확률을 고려하면 쉽게 계산할 수 있습니다.) validation 결과는 87.5% 정도로 나왔습니다.

Random Forest classifier의 feature 중요도는 위와 같습니다. LoL은 상대방 기지를 파괴하는 공성게임 장르(MOBA, AOS)이므로 타워와 억제기 파괴 횟수가 승리에 큰 영향을 준다고 나왔습니다.
4) Gradient Boosting Classifier

다음은 boosting 기법을 이용한 Gradient Boosting Classifier를 사용하여 학습해봤습니다. boosting 기법은 약한 classifier를 여러 개 연결하여 강한 classifier를 만드는 앙상블 기법을 말합니다.
boosting의 아이디어는 앞의 모델을 보완해가면서 일련의 classifier를 학습시키는 것입니다. gradient boosting은 이전 classifier가 만든 잔여 오차(residual error)를 새로운 classifier에 학습시키는 방식으로, 강한 classifier를 앙상블하여 만듭니다.
Gradient Boosting Classifier의 학습 결과는 정확도 87%가 나왔습니다.

Gradient Boosting Classifier의 Feature 중요도도 타워와 억제기가 높게 나왔습니다. 특히 towerKills의 중요도가 매우 높게 나왔으며, 이는 상대 넥서스를 부수고 승리하기 위해서는 상대방의 Tower를 반드시 파괴해야 하기 때문입니다.
5) XGBoost

다음은 XGBoost(eXtreme Gradient Boosting)으로 예측해봤습니다. 매우 빠른 속도와 확장성, 이식성을 목표로, Gradient Boosting 알고리즘을 분산환경에서도 실행할 수 있도록 구현해둔 라이브러리입니다.
정확도는 87% 정도로 앞서 살펴본 classifier와 비슷했습니다.
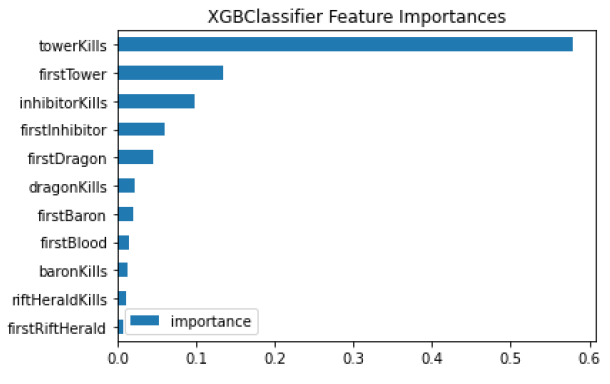
XGBClassifier 역시 tower feature를 중요하게 평가하고 있었으며, 승리한 팀은 상대방의 타워를 많이 파괴했다는 직관적인 사실을 확인할 수 있습니다.
6) LightGBM
마지막으로 LightGBM으로 예측해보겠습니다. LightGBM은 역치 조건에 따라 데이터 분기를 반복하여 회귀 및 분류에 많이 사용하는 결정 트리를 순서대로 갱신해 나가는 그레디언트 부스팅 결정 트리 기법을 구현하는 방법 중 하나입니다. 이것은 실행 속도가 다른 기법들에 비해 빠르고 결측치나 카테고리 변수가 포함된 상태에서도 모델을 학습시킬 수 있다는 장점을 가지고 있습니다.

LightGBM 역시 정확도는 88%로 앞선 것들과 비슷했고 importance도 towerKills가 가장 높게 나와 여전히 towerKills가 승패에 큰 영향을 끼치고 있음을 알 수 있었습니다.
4. 프로젝트 개선 및 결과

1) 예측모델 문제점
- 모든 모델에서 towerKills feature를 가장 중요한 feature로 뽑았으며, 해당 feature에 대한 의존도가 높음
LoL은 상대방의 기지(Nexus)를 파괴하는 게임이므로, 당연히 상대방의 타워를 많이 파괴할수록 높은 승률이 보장
- 상대 타워를 많이 파괴했지만 패배한 경우를 예측하지 못함
tower 관련 feature에 대한 의존도가 높다보니, tower를 많이 부셨음에도 패배한 팀의 승패를 예측하지 못함

이에 towerKills의 중요도를 낮춰보고자, 극단적으로 4개 이상 파괴한 경기를 제외해도 의존도는 비슷했습니다.

극단적으로 towerKills feature를 제거하고 모델 학습을 해도, inhibitorKills와 firstTower feature가 그 자리를 대신할 뿐, 타워와 억제기의 의존도는 상당히 높았습니다.
2) 모델 개선
위 문제점은 다른 feature 들에 비해서, towerKills가 승리에 미치는 영향이 너무 크기 때문이라고 생각했습니다. 따라서, LoL의 또 다른 승리 요소인 ‘챔피언’(플레이어) 관련 feature를 추가했습니다.


위와 같은 12개의 feature를 추가로 선정했으며, 해당 feature는 챔피언의 성장과 관련있는 특성들입니다. 즉, 해당 feature가 높을수록 아군의 챔피언이 강함을 나타냅니다.

Total Dataset의 Boxplot입니다. box plot을 보면 ‘ChampionDamageDealt’, ‘TotalHeal’, ‘ObjectDamageDealt’의 이상치가 상당히 많음을 알 수 있습니다. 따라서 해당 feature는 제외하는 걸 고려해볼 수 있습니다.
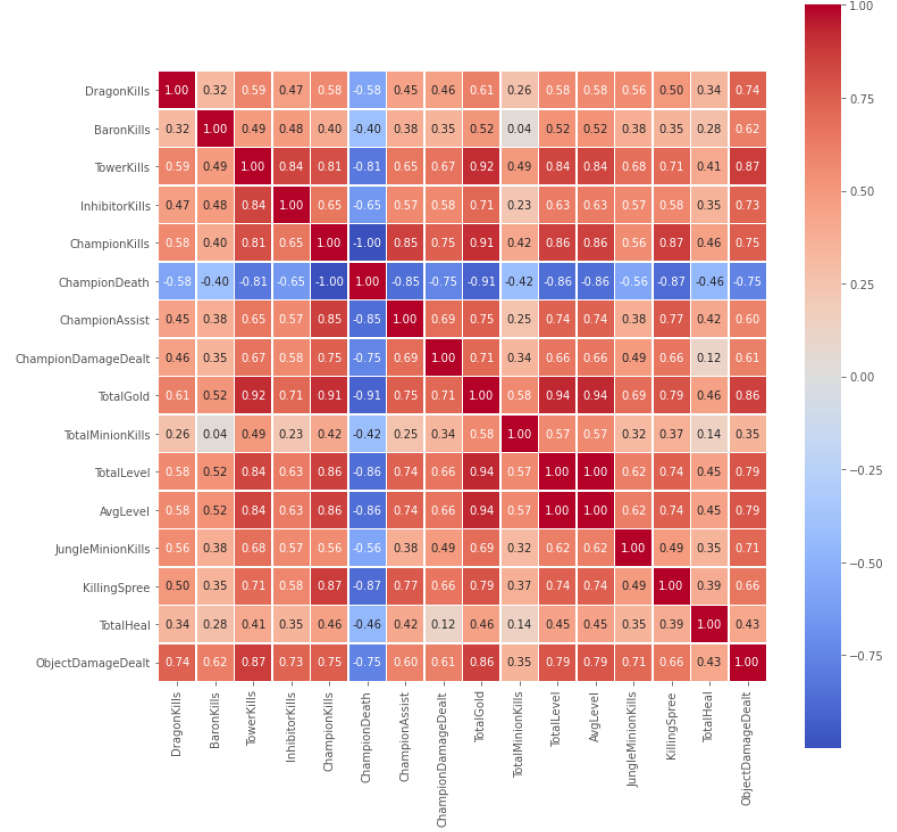
수치형 데이터의 상관관계표를 히트맵으로 시각화하여 살펴보면 위와 같습니다. 유일하게 낮을수록 승리에 유리한 feature인 ‘ChampionDeath’(아군의 챔피언이 죽은 횟수) 특성만이 음의 상관관계를 가지는 걸 확인할 수 있습니다.
또한 챔피언 성장(육성)에 관련된 feature들도 서로 강한 연관성을 지님을 알 수 있습니다. 타워를 파괴하면 보상 골드를 지급하며, 상대 챔피언을 처치하면 보상 골드와 경험치를 지급합니다. 이 때문에 TotalGold와 TotalLevel, TowerKills의 상관성이 높게 나왔으며, 3가지 요소가 승리에 큰 영향을 끼친다는 점을 직관적으로 알 수 있습니다.

이제 추가된 feature를 통해 다시 모델 학습을 진행합니다. 4.2에서와 마찬가지로 범주형 데이터를 인코딩하고, 수치형 데이터를 standard scaler로 표준화하는 과정을 거칩니다.
챔피언 성장과 관련된 9개의 feature를 추가하여, logistic Regression을 수행한 결과 이전보다 훨씬 좋은 성능을 보여줬습니다. ( ‘ChampionDamageDealt’, ‘TotalHeal’, ‘ObjectDamageDealt’는 이상치가 많아서 제거했습니다.) 이전에는 87%에 그쳤지만, 챔피언 성장 요소를 추가하니 99%에 가까운 정확도를 얻을 수 있었습니다.
상대방의 기지를 파괴하는 공성게임장르이므로 단순히 타워와 관련된 Feature만 고려할 게 아니라, 챔피언[플레이어]과 관련된 Feature도 고려해야 좋은 정확도를 얻을 수 있었습니다. 게임의 주인공은 ‘플레이어’(챔피언)인데, 플레이어에 대한 feature 정보가 부족해서 이전에는 구분하지 못했던 경기들이 13%나 되었습니다. 이를 플레이어에 대한 정보를 추가하여 극복할 수 있었습니다.

학습모델로 실제 경기 데이터를 넣고 실시간 승률을 예측했습니다. 게임의 판세가 엎치락 뒤치락하면서, 실시간 승률도 요동치는 걸 볼 수 있습니다.
3) 프로젝트 의의 및 기대효과
- E-Sports 라이브 중계 시, 실시간 승률 예측
: E-sport 관객들이 경기를 관람하는 데에 좋은 보조 자료가 됩니다. 어느 팀이 얼마나 유불리한지를 알 수 있으며, 한 번의 전투를 통해 승률이 크게 뒤바뀌는 극적인 상황도 연출할 수 있습니다.
- 게임 전략 분석
: 승패에 영향을 끼치는 전략요소가 무엇인지에 대한 인사이트를 플레이어에게 제공합니다.
- 자신의 게임 복기
: 자신이 플레이한 경기의 리플레이를 복기하며, 승률이 크게 내려간 지점이나 오른 지점을 찾아 팀의 승패 원인을 분석할 수 있습니다

'Projects' 카테고리의 다른 글
| [Project] STRC 러닝 데이터베이스: 러닝크루 기록 관리 (0) | 2022.06.05 |
|---|---|
| [Project] Patent Server: 특허 빅데이터 분석 플랫폼 (9) | 2022.03.24 |
| [Project] ST Fair Route: 모두가 공평한 네비게이션 앱 (0) | 2022.03.23 |
| [Project] Cartpole: DQN, DDQN, Dueling DQN 강화학습 (0) | 2022.03.22 |
| [Project] Patent Big Data Analysis: 자연어 처리를 이용한 특허문서 분석 (1) | 2022.03.17 |




댓글