[ Project ]
1. 프로젝트 개요
- 분류: 데이터 분석
- 일시: 2020.10. ~ 2020.12.
- 스택: Apache Spark, Scala
- 주제:자연어 처리를 이용한 특허문서 분석
GitHub - jangThang/Patent_BigDataAnalysis
Contribute to jangThang/Patent_BigDataAnalysis development by creating an account on GitHub.
github.com
2. 프로젝트 소개

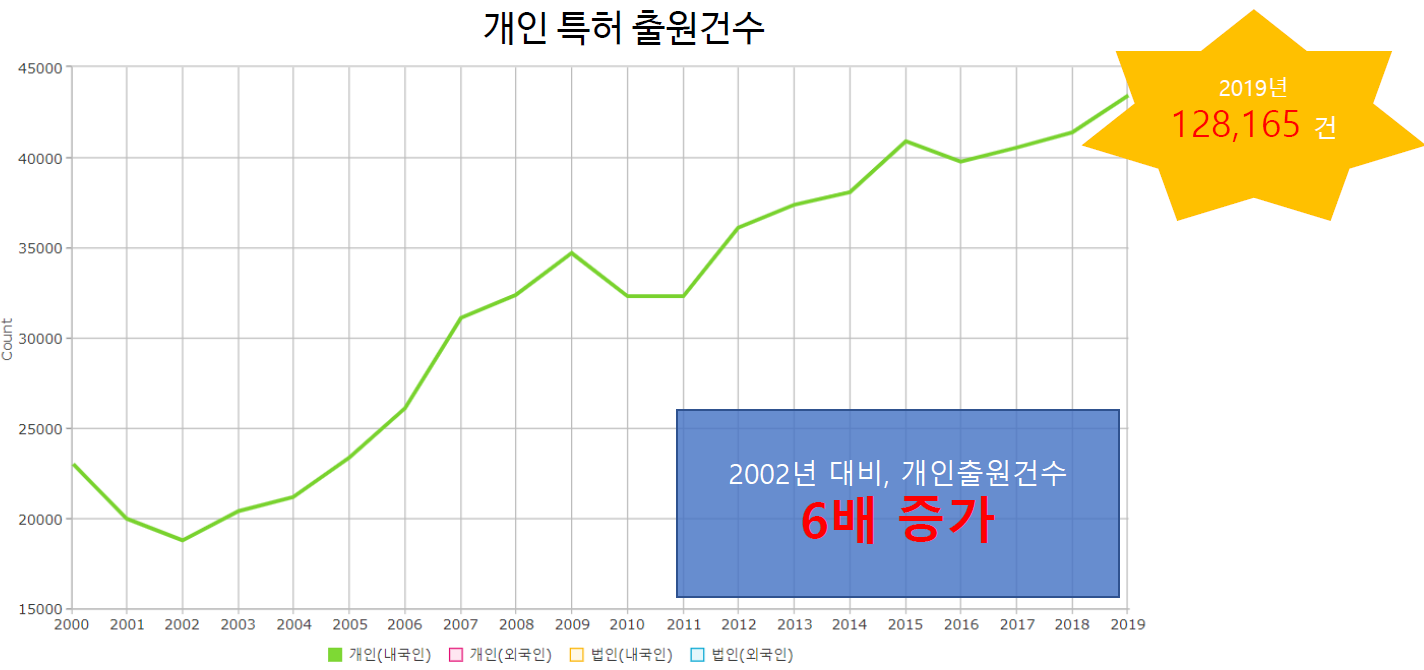
대한민국은 GDP-인구 대비 특허출원 세계 1위로, 개인 특허 출원건수가 2002년 대비 6배나 증가했습니다. 여기서 '특허 출원'이란, 특허를 등록하기 위해 신청하는 걸 뜻합니다.
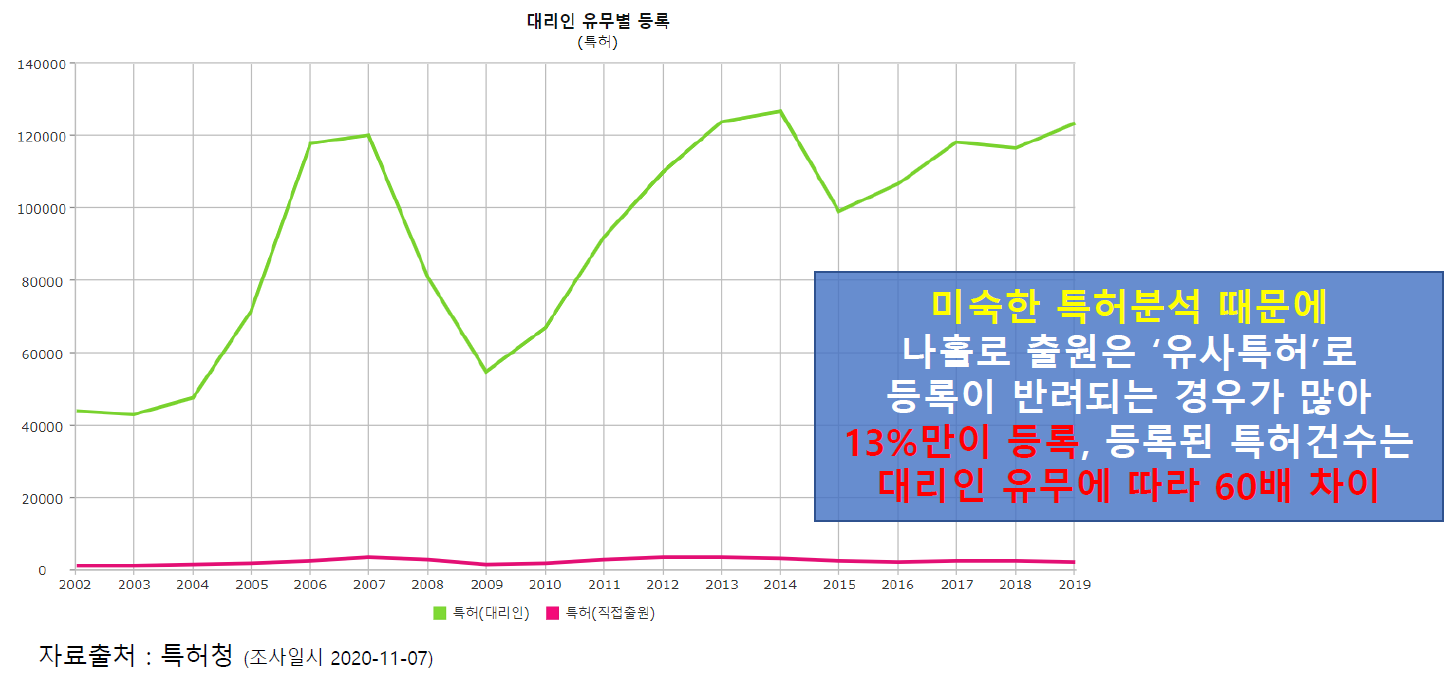
하지만 개인 특허 출원인은 '유사특허'로 인해 등록이 반려되는 경우가 90%에 육박하며, 대부분의 특허는 '대리인(변리사)'이 대신 등록해줍니다.
특허 등록이 거부되는 경우, 100만원이 넘는 등록비와 1년 6개월에 달하는 출원 기간을 낭비하게 됩니다. 특히, 출원 기간 동안 특허등록이 된다는 전제 하에 사업을 준비하던 출원자들에게는 더 큰 손실로 이어집니다.

개인 특허 출원자들이 '유사 특허'를 발견하지 못하는 이유는 '선행기술조사'와 '특허분석'이 미숙하기 때문입니다. 실제 특허사무소에서는 많은 인력과 시간을 들여, 특허 문서를 일일이 분류하고 분석합니다. 하지만 개인은 그러한 시간과 능력이 부족합니다.
따라서 해당 프로젝트는 개인 특허 출원자가 막대한 비용을 들여 '특허 사무소'에 의뢰하지 않고도 특허 분석을 할 수 있도록, 자연어 처리를 이용해 특허 분석을 실시했습니다.
● 프로젝트 배경
- 개인 특허 출원자의 가파른 증가세에도, 등록율이 저조함 (13%)
- 개인이 특허 분석을 통해 '유사 특허'를 검출하기 어려움 (시간과 노력 부족)
- 울며 겨자먹기로 막대한 비용을 지불해서 특허 사무소에 의뢰해야만 현실적으로 특허 등록 가능
● 프로젝트 목표
- 어려운 특허분석을 자연어 처리를 이용해서 쉽고 빠르게 분석
- Word2Vec 분석을 통해 특허 범위 내 유효한 검색식 도출
- LSA(Latent Semantic Analysis) 분석을 통해 특허범위 내 기술분류 도출
3. 기능 및 구성
1) 청구항 데이터 추출 및 전처리
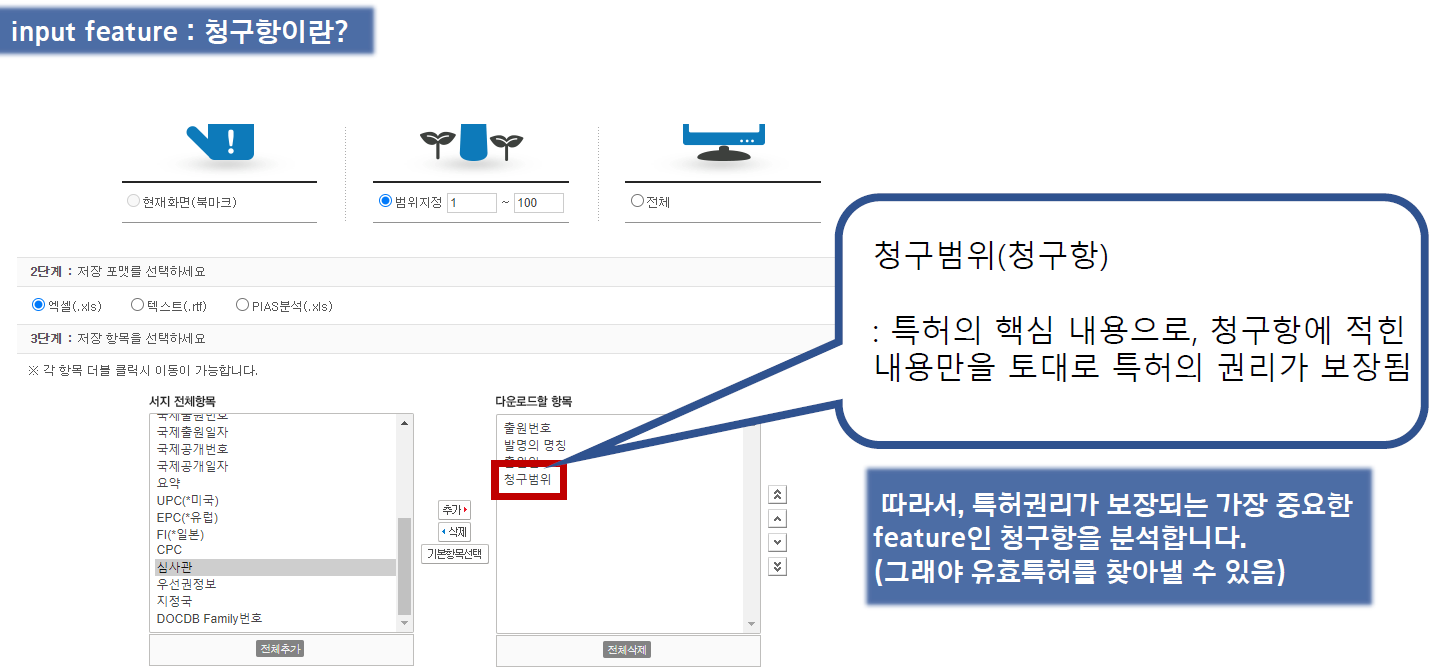
청구항은 특허 문서의 핵심으로, 청구항에 쓰인 내용만으로 권리가 보장됩니다.
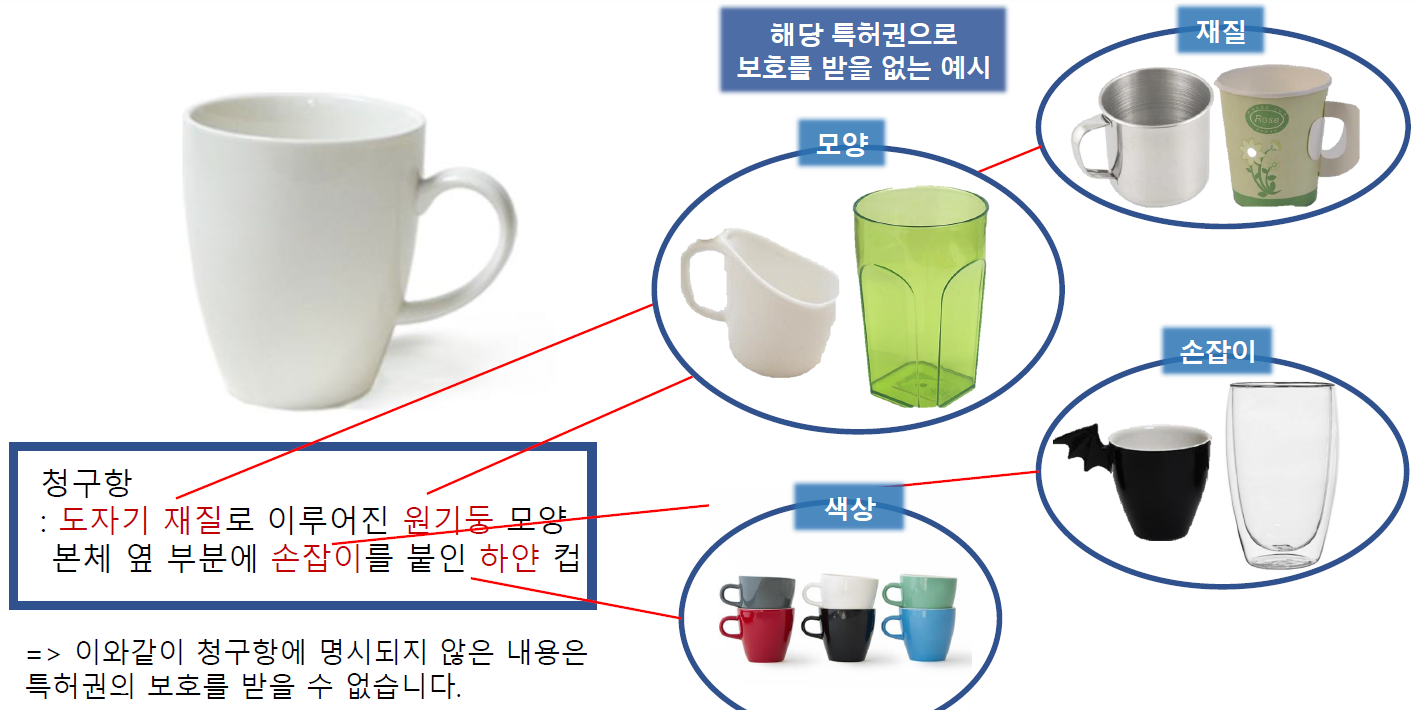
예를 들어, 청구항이 위와 같이 '도자기 재질로 이루어진 원기둥 모양 본체 옆 부분에 손잡이를 붙인 하얀 컵'이라고 합시다. 그러면 다른 재질이나 모양, 색상의 컵은 특허 권리를 인정받을 수 없습니다.
청구항에 명시된 내용만 특허로 인정되기 때문에, 특허 문서 중에 '청구항'을 분석하면 유사 특허를 찾아낼 수 있습니다. 특허 문서의 청구항은 대개 1~2페이지로, 1문장이 5~6줄 이상입니다. 청구항의 개수가 많을수록 등록비용이 비싸지므로, 대부분 하나의 항에 최대한 많은 내용을 담습니다. 게다가 법조체와 비슷해서 가독성도 상당히 좋지 못합니다.

이러한 청구항을 분석하기 위해, 전처리 작업을 실시합니다. 총 3단계로, Apache-Spark에서 분석할 수 있도록 RDD로 변환하고 단어 단위로 나누고, 불용어를 제거합니다. 여기서 RDD는 Resilient Distributed Dataset로, 스파크의 기본 데이터 구조입니다. 불용어는 필요 없는 미사여구로, 관사나 감탄어구 등이 있습니다.

일일이 데이터 전처리를 할 수도 있지만, 효율이 좋은 라이브러리를 굳이 안 쓸 이유는 없습니다. 영문 전처리에 유용한 Stanford NLP를 사용하여 전처리 작업을 마쳤습니다.
The Stanford Natural Language Processing Group
The Stanford NLP Group The Natural Language Processing Group at Stanford University is a team of faculty, postdocs, programmers and students who work together on algorithms that allow computers to process, generate, and understand human languages. Our work
nlp.stanford.edu
2) Word2Vec 분석으로 '검색식' 도출

검색식은 키워드와 논리 연산자로 구성된 식으로, 특허 DB에서 특허문서를 검색할 때 사용합니다. 검색식을 잘 구성해야 유효 특허를 검출할 수 있습니다. 이 때문에 특허 사무소에서는 1개월에서 3개월을 검색식만 찾는 경우도 있습니다.
하지만 개인 특허 출원자들은 단순히 몇 개의 키워드로 조합한 검색식으로 조사를 마칩니다. 미숙한 검색식 사용으로 유사특허를 놓치게 됩니다.

Word2Vec은 단어를 벡터화해서 단어들 간의 유사도를 측정하는 자연어 처리기법입니다. 해당 기법을 이용하면 키워드와 유사한 단어들을 추출할 수 있습니다. 그중 특허 범위와 관련 있는 단어는 OR, AND 연산으로 추가하고, 관련 없는 단어는 NOT 연산으로 제거합니다.

이를 여러 번 반복하면, 유효한 검색식을 도출할 수 있습니다. 현업에서 사용하는 검색식도 3~4줄 정도로 길며, 여러 개를 사용합니다.
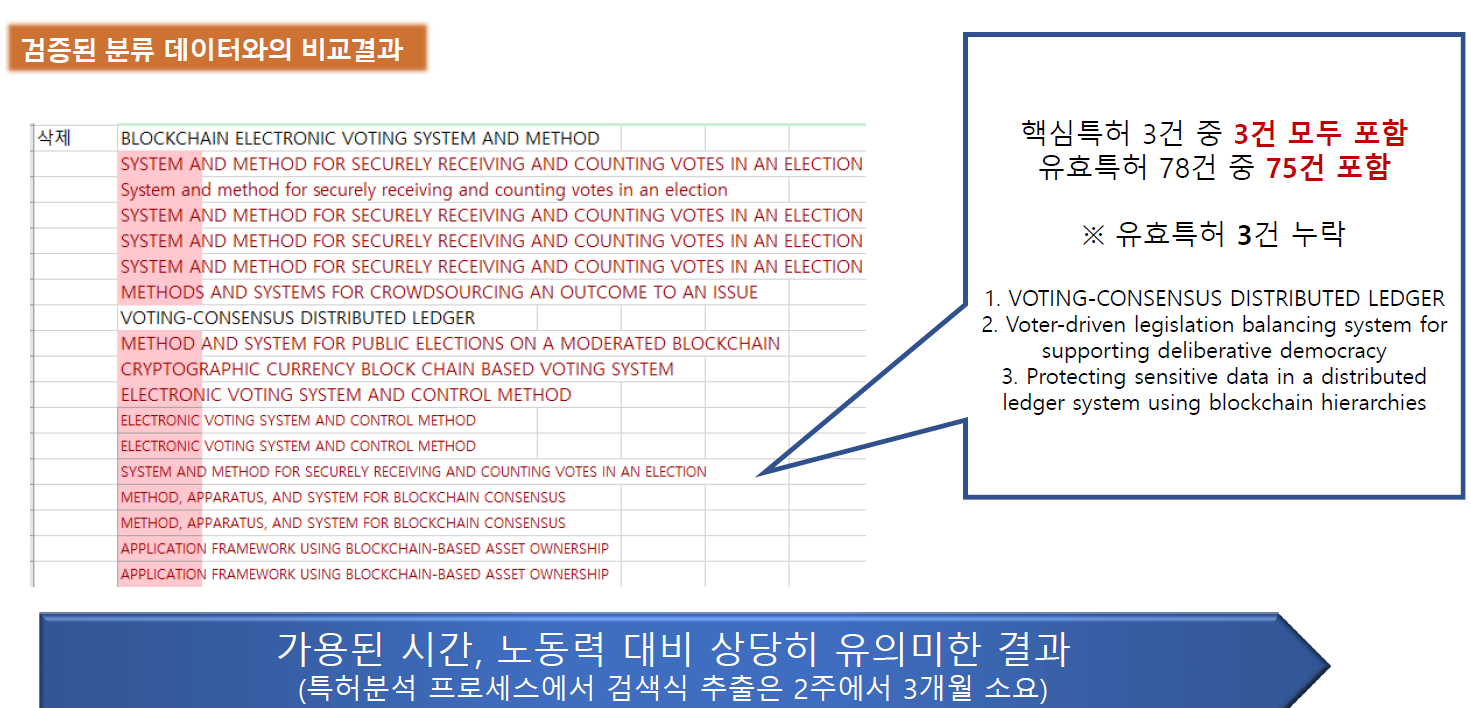
특허 전문가로부터 공인받은 '전자투표-블록체인' 데이터셋을 사용해 검증을 마쳤으며, 유의한 결과를 얻었습니다.
3) LSA 분석으로 '기술분류' 도출

기술분류는 특허범위 내 특허문서를 일일이 기술별로 분류한 표입니다. 기술분류표를 통해 어떤 기술이 활발히 연구되고 있는지 알 수 있으며, 연구가 덜 된 블루오션도 발견할 수 있습니다.
하지만 위 표는 일일이 특허문서를 읽고 분류해야 하며, 관련 분야의 전문성도 겸비해야 합니다. 따라서 엄청난 노동력과 시간을 필요로 합니다.

이를 LSA 분석을 통해 해결할 수 있습니다. LSA 분석은 키워드와 문서, 토픽 간의 유사도를 측정하는 자연어 처리 기법으로, 주요 토픽과 관련된 키워드와 특허 문서를 찾을 수 있습니다.
주요 키워드와 특허 문서를 통해 '주요 테마'를 찾을 수 있으며, 이를 통해 기술분류표를 작성할 수 있습니다.
4. 프로젝트 필요성 및 기대효과
1) 필요성
- 늘어나는 개인 특허 출원자 수에 비해, 저조한 등록률 (13%)
GDP-인구 대비 특허출원율 1등으로, 개인 특허 출원자도 2002년 대비 6배나 증가했습니다. 하지만 등록률은 13% 정도로 대부분 등록을 거절당하며, 이로 인해 막대한 시간과 비용을 낭비하게 됩니다. (등록비용: 100만원↑, 출원 기간: 18개월)
- 개인이 특허 분석하기 어려움
특허사무소에 비해 개인은 전문성과 노동력, 시간이 절대적으로 부족합니다. 특히 유사 특허를 찾아내는 '선행기술조사'와 IP-R&D 프로세스 중 80 ~ 90% 시간과 비용을 차지하는 '특허 분석'은 매우 중요하지만 개인이 하기가 어렵습니다.
- 특허 등록에 많은 비용과 시간이 필요
개인이 제대로 특허 분석을 하려면 많은 시간과 노동력, 전문성이 필요합니다. 이는 특허 사무소도 마찬가지로, 매번 수많은 특허문서를 읽고 분류하고 분석하는 작업을 반복해야 합니다.
2) 효과
- 개인이 혼자 할 수 있을 만큼 적은 시간과 노동력으로 분석 가능
자연어 처리 기법을 이용하면, 수많은 특허문서를 빠르게 분석하고 결과를 얻을 수 있습니다. Word2Vec 기법으로 유의한 검색식을 도출하고, LSA 기법으로 기술분류표를 탐색합니다.
- 주요 특허분야는 기본 10만 ~ 100만 건으로, 더 큰 효익 기대
반도체, 고체연료, 2차전지와 같이 주요 특허분야는 기본 10만 ~ 100만 건이 넘어갑니다. 이러한 특허 분야를 조사하는 데에 자연어 처리 기법은 더 큰 효용을 얻습니다. 일일이 사람이 읽고 분류하고 분석할 필요가 없습니다.
- 특허장벽의 문턱을 낮추고, 유용한 특허분석도구로 사용 가능
기존에는 어려운 특허분석 프로세스 때문에 개인이 특허 조사하기 어려웠으며, 특허사무소에 거금을 들여 조사를 의뢰해야 했습니다. 하지만, 해당 프로젝트를 이용하면 매우 적은 비용으로 빠르게 분석을 마칠 수 있습니다.

'Projects' 카테고리의 다른 글
| [Project] ST Fair Route: 모두가 공평한 네비게이션 앱 (0) | 2022.03.23 |
|---|---|
| [Project] Cartpole: DQN, DDQN, Dueling DQN 강화학습 (0) | 2022.03.22 |
| [Project] SNUT RoadSign: SeoulTech 길찾기 프로그램 (0) | 2022.03.16 |
| [Project] Seoultech Explore: 모교 홍보를 위한 웹 게임(퀴즈) (0) | 2022.03.15 |
| [Project] 게시판 소개 (0) | 2022.01.09 |




댓글